Code
library(tidysynth)
library(wbstats)library(tidysynth)
library(wbstats)Data Source: World Bank Development Indicators
Time Period: 2003 - 2015
Countries: Algeria, Angola, Bahrain, Ecuador, Egypt, Iran, Israel, Jordan, Lebanon, Morocco, Nigeria, Oman, and Saudi Arabia.
Outcome Variable: military expenditure (current US$) per capita.
Control Variables: total population, imports of goods and services (constant US$), GDP per capita (constant US$) and real GDP per capita growth rate.
Special Variables: military spending per capita in years 2010, 2008, 2006 and 2004
# Load Data from World Bank
wb_countries <- wb_countries("en")
countries <- c(
"Bahrain", "Ecuador", "Egypt, Arab Rep.",
"Iran, Islamic Rep.", "Israel", "Jordan",
"Lebanon", "Morocco", "Nigeria",
"Oman", "Saudi Arabia"
)
country_iso2c <- wb_countries |>
dplyr::filter(country %in% countries) |>
dplyr::pull(iso2c)
ind <- wb_indicators("en", include_archive = FALSE)
vars <- c(
"MS.MIL.XPND.CD","SP.POP.TOTL",
"NE.IMP.GNFS.KD", "NY.GDP.PCAP.KD",
"NY.GDP.PCAP.KD.ZG", "BM.GSR.GNFS.CD"
)
ind |>
dplyr::filter(indicator_id %in% vars)# A tibble: 6 × 8
indicator_id indicator unit indicator_desc source_org topics source_id source
<chr> <chr> <lgl> <chr> <chr> <list> <dbl> <chr>
1 BM.GSR.GNFS… Imports … NA Imports of go… Internati… <df> 2 World…
2 MS.MIL.XPND… Military… NA Military expe… Stockholm… <df> 2 World…
3 NE.IMP.GNFS… Imports … NA Imports of go… World Ban… <df> 2 World…
4 NY.GDP.PCAP… GDP per … NA GDP per capit… World Ban… <df> 2 World…
5 NY.GDP.PCAP… GDP per … NA Annual percen… World Ban… <df> 2 World…
6 SP.POP.TOTL Populati… NA Total populat… (1) Unite… <df> 2 World…df <- wb_data(indicator = vars, country = country_iso2c, start_date = 2002, end_date = 2015)
# Check all variables and countries are in the data frame.
all(vars %in% names(df)) & all(country_iso2c %in% unique(df$iso2c))[1] TRUE# Process Data
sanctions <- df |>
dplyr::mutate(
milspend_pc =MS.MIL.XPND.CD/SP.POP.TOTL,
realgdpgrowth_pc = NY.GDP.PCAP.KD/dplyr::lag(NY.GDP.PCAP.KD,1)-1,
country_id = match(iso2c, country_iso2c),
imports = ifelse(is.na(NE.IMP.GNFS.KD), BM.GSR.GNFS.CD,NE.IMP.GNFS.KD), ## TODO convert to constant prices.
) |>
dplyr::select(
country_id,
country,
year = date,
milspend_pc,
pop = SP.POP.TOTL,
imports,
realgdp_pc = NY.GDP.PCAP.KD,
realgdpgrowth_pc
) |>
dplyr::filter(year>=2003) sanctions_out <- sanctions %>%
synthetic_control(outcome = milspend_pc,
unit = country,
time = year,
i_unit = "Iran, Islamic Rep.",
i_time = 2011,
generate_placebos=T
) %>%
generate_predictor(time_window = 2003:2011,
pop = mean(pop),
imports = mean(imports),
realgdp_pc = mean(realgdp_pc),
realgdpgrowth_pc = mean(realgdpgrowth_pc)) %>%
generate_predictor(time_window = 2010,
milspend_2010 = milspend_pc) %>%
generate_predictor(time_window = 2008,
milspend_2008 = milspend_pc) %>%
generate_predictor(time_window = 2006,
milspend_2006 = milspend_pc) %>%
generate_predictor(time_window = 2004,
milspend_2004 = milspend_pc) %>%
generate_weights(optimization_window = 2003:2011,
margin_ipop = .02,sigf_ipop = 7,bound_ipop = 6
) %>%
generate_control()Once the synthetic control is generated, one can easily assess the fit by comparing the trends of the synthetic and observed time series. The idea is that the trends in the pre-intervention period should map closely onto one another.
sanctions_out %>% plot_trends()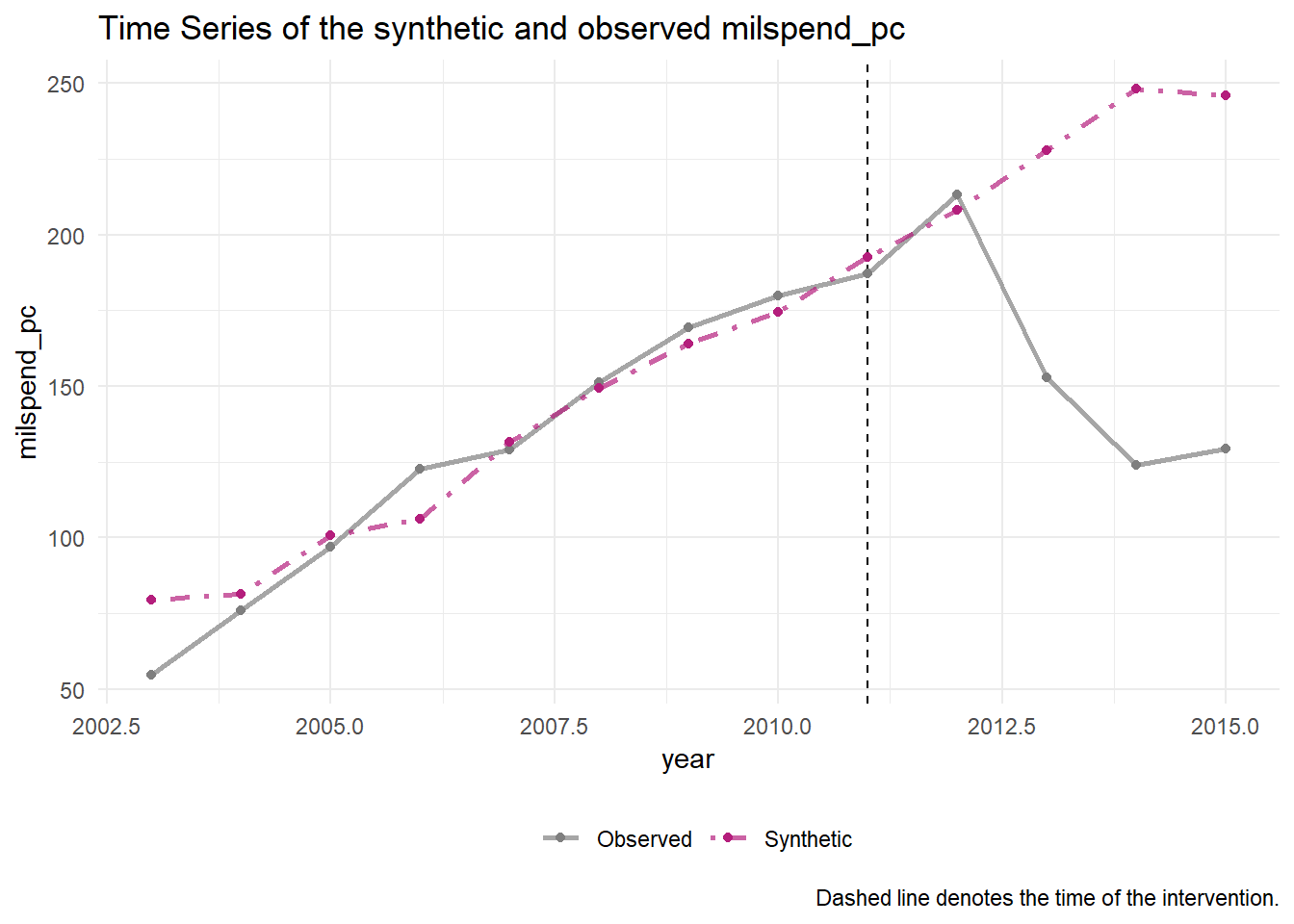
To capture the causal quantity (i.e. the difference between the observed and counterfactual), one can plot the differences using plot_differences()
sanctions_out %>% plot_differences()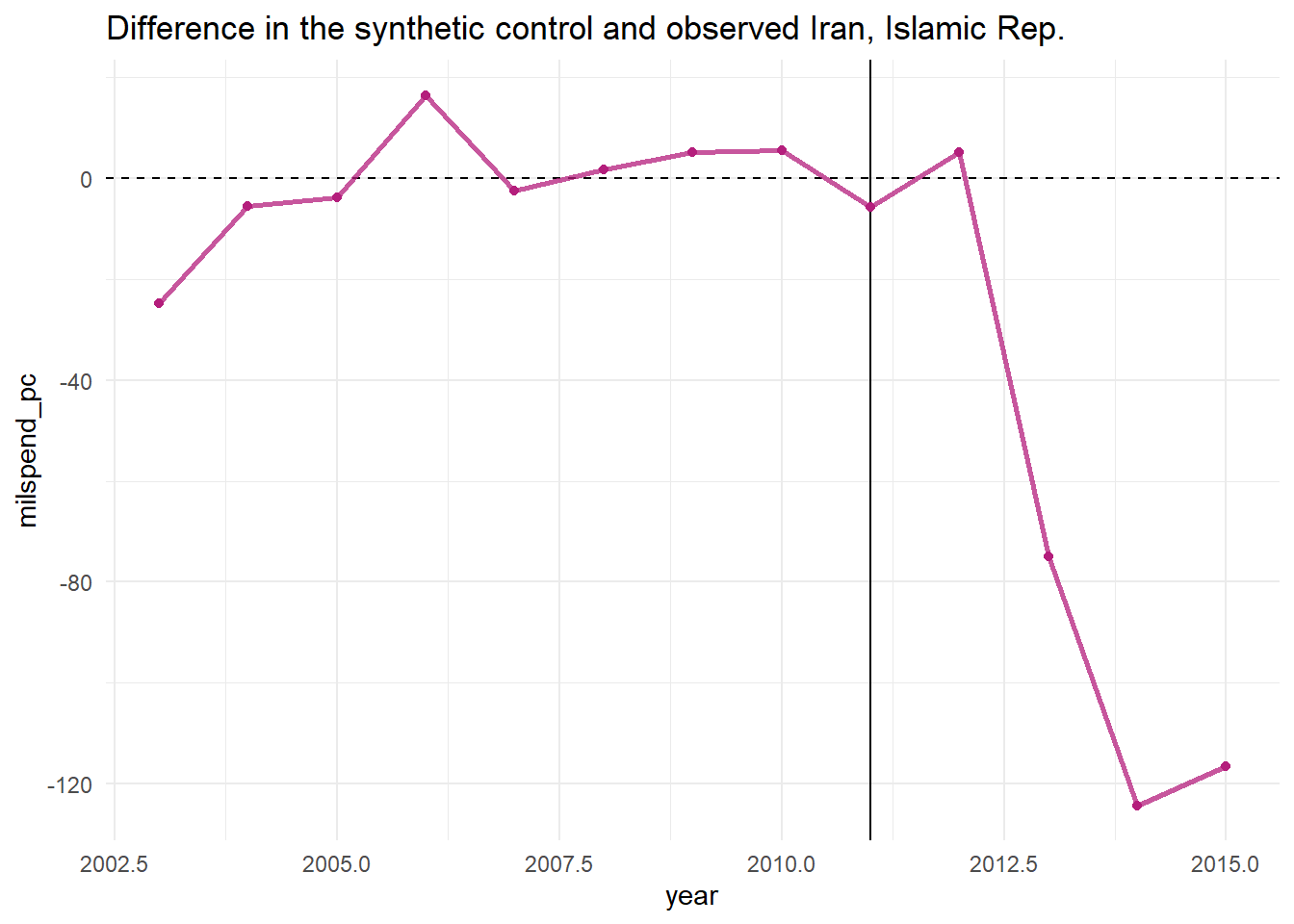
In addition, one can easily examine the weighting of the units and variables in the fit. This allows one to see which cases were used, in part, to generate the synthetic control.
sanctions_out %>% plot_weights()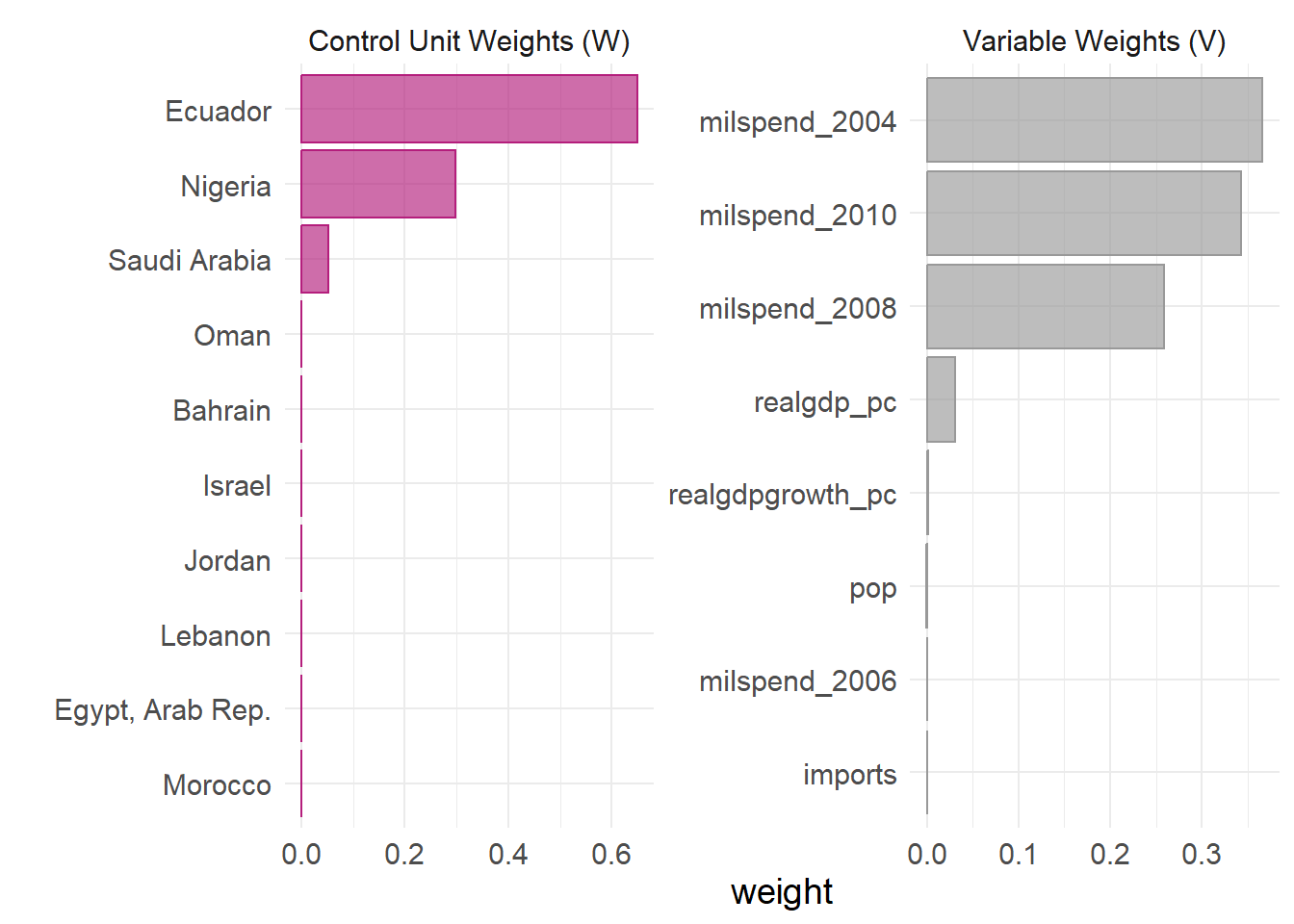
Another useful way of evaluating the synthetic control is to look at how comparable the synthetic control is to the observed covariates of the treated unit.
sanctions_out %>% grab_balance_table()# A tibble: 8 × 4
variable `Iran, Islamic Rep.` synthetic_Iran, Islamic R…¹ donor_sample
<chr> <dbl> <dbl> <dbl>
1 imports 1.66e+11 5.34e+10 4.94e+10
2 pop 7.22e+ 7 5.50e+ 7 3.25e+ 7
3 realgdp_pc 5.03e+ 3 4.86e+ 3 1.16e+ 4
4 realgdpgrowth_pc 2.89e- 2 3.20e- 2 2.48e- 2
5 milspend_2010 1.80e+ 2 1.74e+ 2 6.17e+ 2
6 milspend_2008 1.51e+ 2 1.49e+ 2 5.94e+ 2
7 milspend_2006 1.23e+ 2 1.06e+ 2 4.77e+ 2
8 milspend_2004 7.59e+ 1 8.14e+ 1 4.16e+ 2
# ℹ abbreviated name: ¹`synthetic_Iran, Islamic Rep.`For inference, the method relies on repeating the method for every donor in the donor pool exactly as was done for the treated unit — i.e. generating placebo synthetic controls). By setting generate_placebos = TRUE when initializing the synth pipeline with synthetic_control(), placebo cases are automatically generated when constructing the synthetic control of interest. This makes it easy to explore how unique difference between the observed and synthetic unit is when compared to the placebos.
sanctions_out %>% plot_placebos()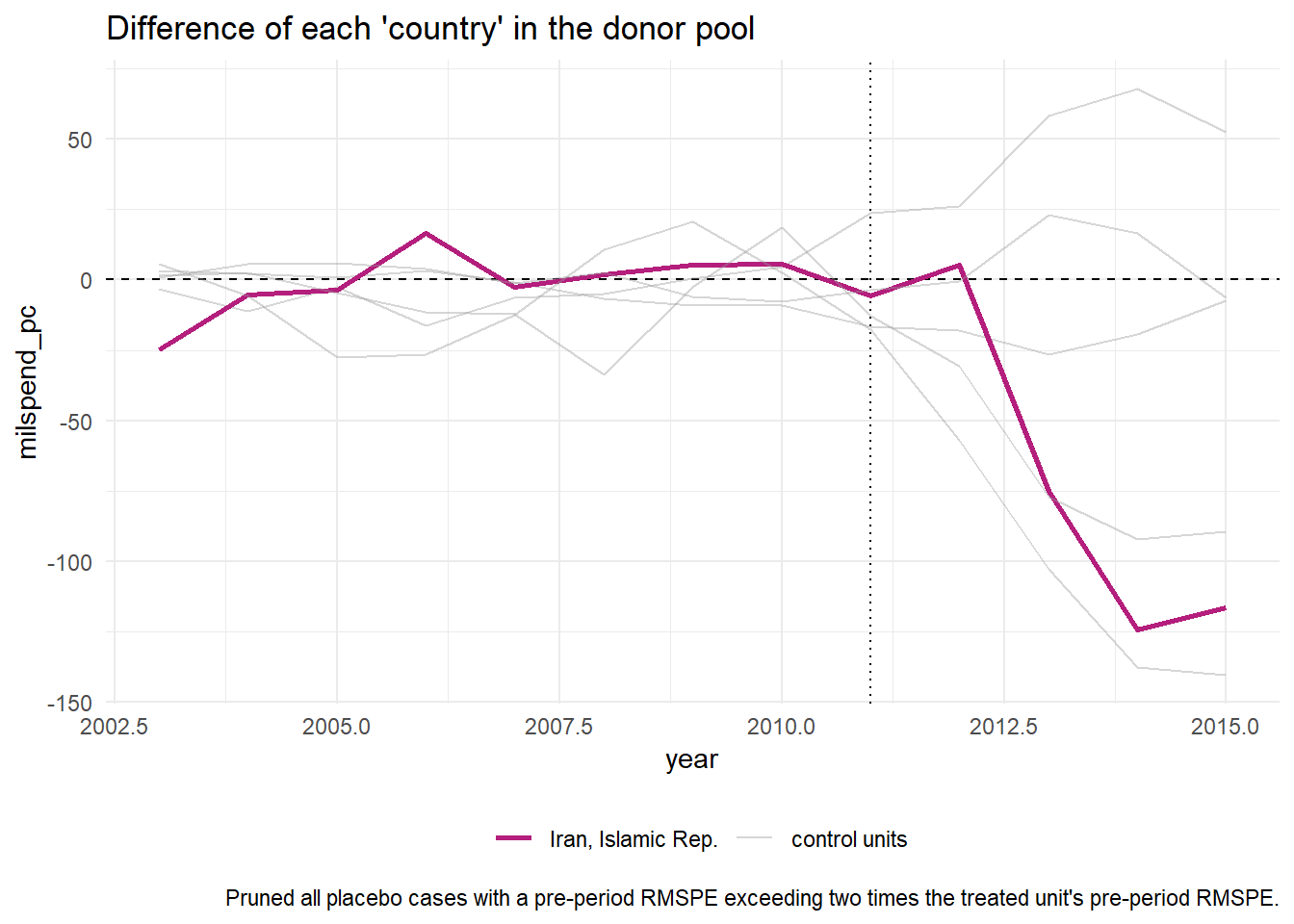
Note that the plot_placebos() function automatically prunes any placebos that poorly fit the data in the pre-intervention period. The reason for doing so is purely visual: those units tend to throw off the scale when plotting the placebos. To prune, the function looks at the pre-intervention period mean squared prediction error (MSPE) (i.e. a metric that reflects how well the synthetic control maps to the observed outcome time series in pre-intervention period). If a placebo control has a MSPE that is two times beyond the target case (e.g. “California”), then it’s dropped. To turn off this behavior, set prune = FALSE.
sanctions_out %>% plot_placebos(prune = FALSE)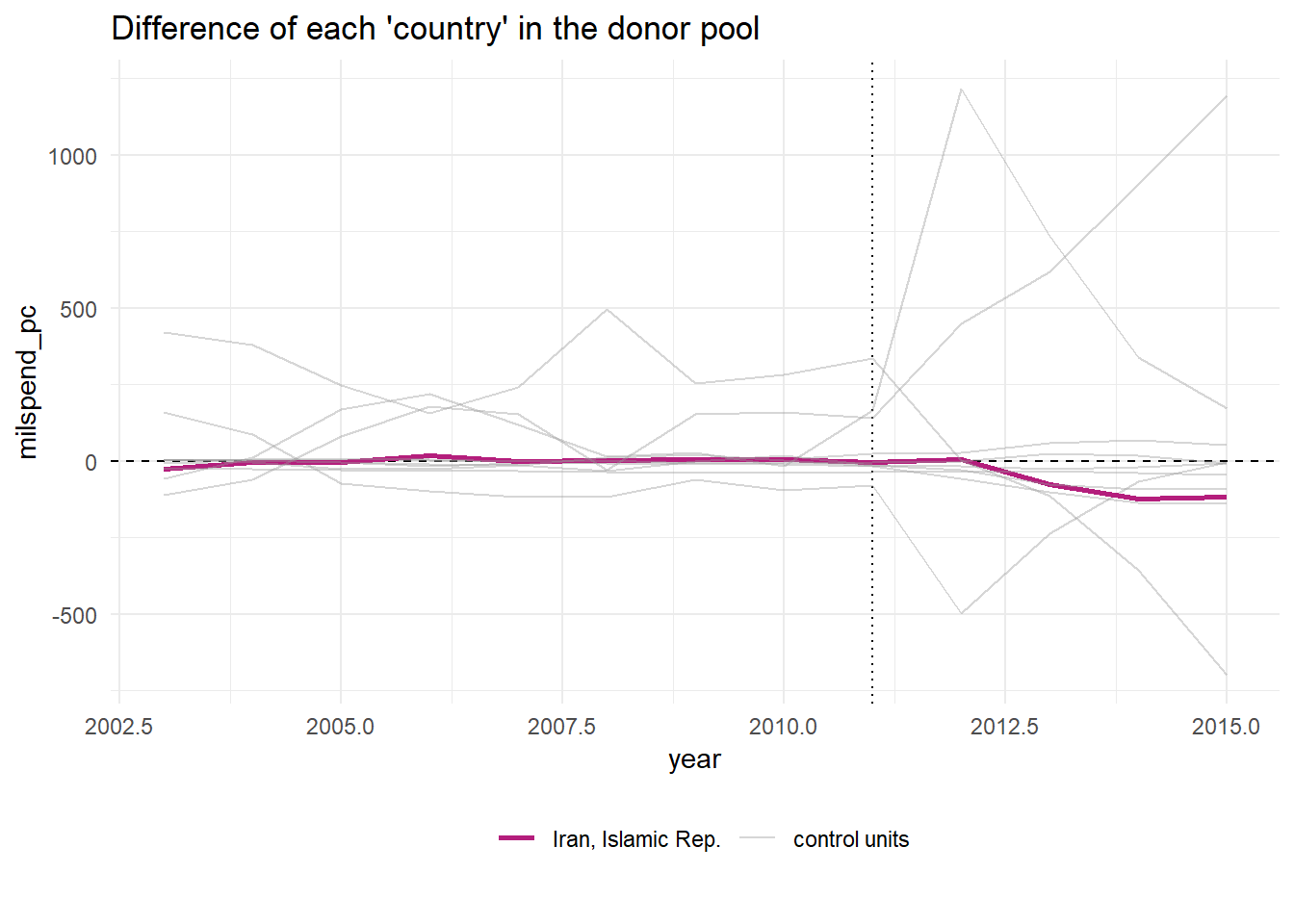
Finally, Adabie et al. 2010 outline a way of constructing Fisher’s Exact P-values by dividing the post-intervention MSPE by the pre-intervention MSPE and then ranking all the cases by this ratio in descending order. A p-value is then constructed by taking the rank/total.1 The idea is that if the synthetic control fits the observed time series well (low MSPE in the pre-period) and diverges in the post-period (high MSPE in the post-period) then there is a meaningful effect due to the intervention. If the intervention had no effect, then the post-period and pre-period should continue to map onto one another fairly well, yielding a ratio close to 1. If the placebo units fit the data similarly, then we can’t reject the hull hypothesis that there is no effect brought about by the intervention.
This ratio can be easily plotted using plot_mspe_ratio(), offering insight into the rarity of the case where the intervention actually occurred.
sanctions_out %>% plot_mspe_ratio()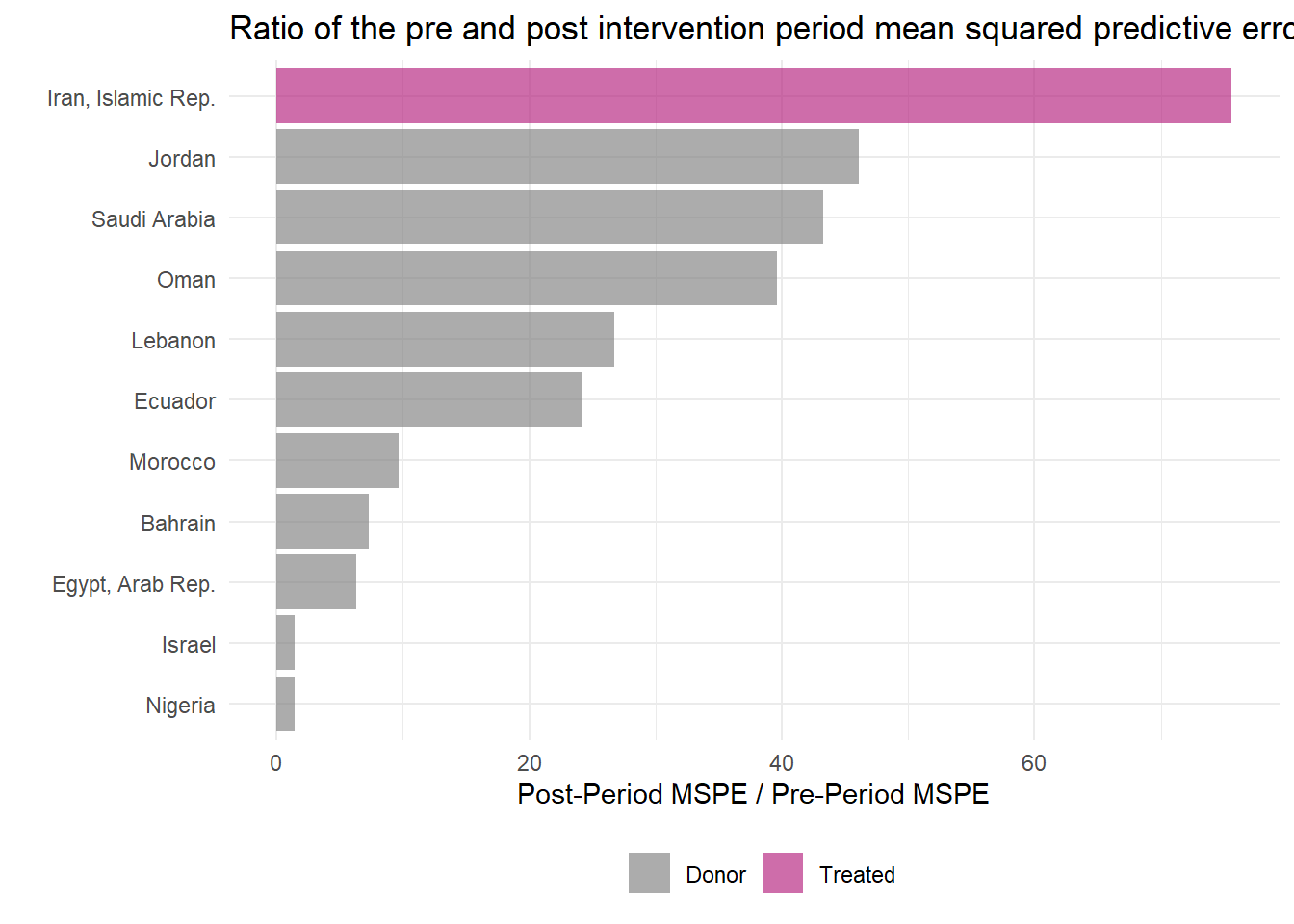
For more specific information, there is a significance table that can be extracted with one of the many grab_ prefix functions.
sanctions_out %>% grab_significance()# A tibble: 11 × 8
unit_name type pre_mspe post_mspe mspe_ratio rank fishers_exact_pvalue
<chr> <chr> <dbl> <dbl> <dbl> <int> <dbl>
1 Iran, Islamic… Trea… 115. 8667. 75.6 1 0.0909
2 Jordan Donor 284. 13107. 46.1 2 0.182
3 Saudi Arabia Donor 16332. 706684. 43.3 3 0.273
4 Oman Donor 13643. 540223. 39.6 4 0.364
5 Lebanon Donor 218. 5839. 26.8 5 0.455
6 Ecuador Donor 118. 2857. 24.3 6 0.545
7 Morocco Donor 21.7 210. 9.69 7 0.636
8 Bahrain Donor 10509. 77008. 7.33 8 0.727
9 Egypt, Arab R… Donor 57.6 365. 6.34 9 0.818
10 Israel Donor 107344. 156612. 1.46 10 0.909
11 Nigeria Donor 1072. 1503. 1.40 11 1
# ℹ 1 more variable: z_score <dbl>